
Some years ago, I participated in a project intended for small companies and entrepreneurs. It was a typical SaaS app with a user register and login mechanism; users could digit products, orders, and sales of the company on the platform. Then, they could visualize a lot of awesome charts and projections, and download them as PDF reports.
The whole project was very conventional from a technical point of view but the report generation part was damn interesting, I will share it in this article.
Requirements
- During this time, I was working with a scalable serverless architecture on Amazon, so I needed to make the PDF generation work on Lambda.
- I had developed the whole business core (calculations, projections, etc. ) using Python, so I was looking for a Pythonic solution as far as possible.
- The PDF reports had to be similar to or with the same visual identity as the content shown on the platform: styles, colors, fonts, etc.
Workaround
I first figured out using a PDF generation library like HTML2PDF or FPDF for example. But years ago, those libraries were quite limited: the generated PDFs were visually poor, and the charts were kind of ugly.
Then I wondered if I could build an HTML template with all the wonderful visual things I need, “take a picture” of it, and “paste” it into a PDF. Good news: this is possible with the library Puppeteer and its Python equivalent Pyppeteer.
Following this idea, we will do the following: run a browser instance on Lambda, go to the HTML template, populate it with user data, generate a PDF file, and keep it in an S3 bucket.
This will be the final architecture of our app:
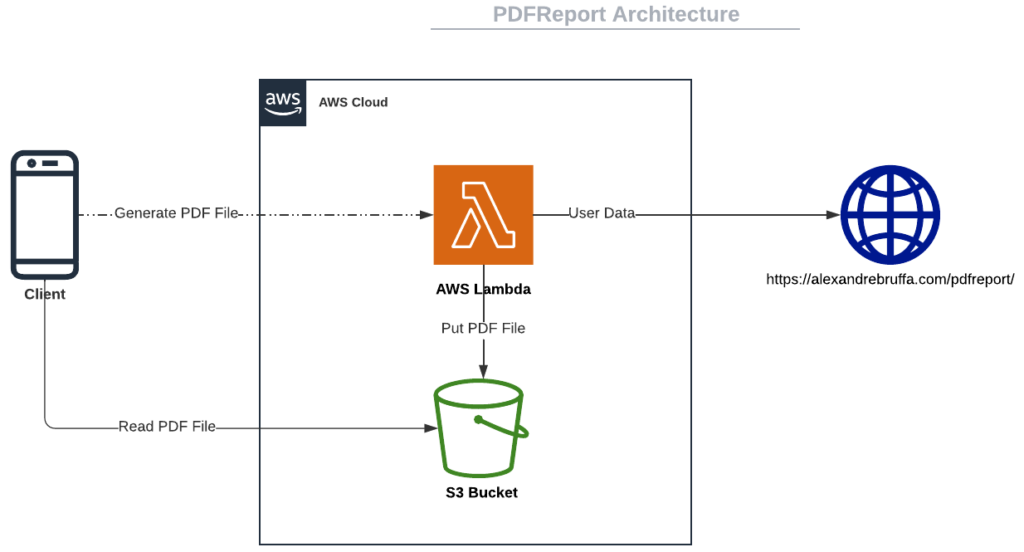
This article will focus on the Lambda part and the PDF generation; I will assume that we already have the user data. If you want to make a great integration with Cognito, API Gateway + Authorizer, and an RDS database, I invite you to read my previous article:
The HTML template
Building the template
First, we need to generate a great-looking HTML template. Since I’m not a designer nor a frontend developer, a good alternative for me is buying an HTML template like the cheap and beautiful Sash Template.
After some HTML, CSS, and Javascript hacks, I obtained this great dummy template without user data:
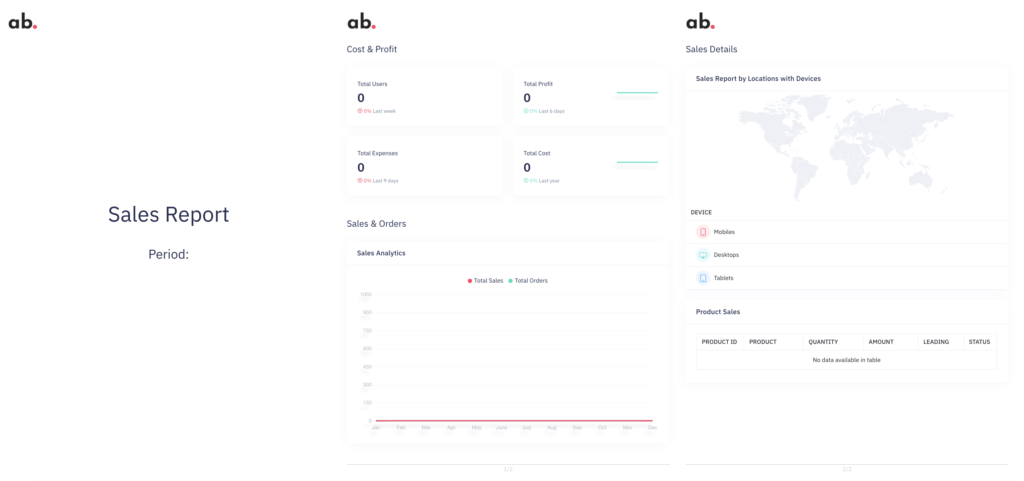
Tip 1: Try to build a template the lighter you can, located on a fast hosting, without big pictures or big files to load. Also, the PDF file will be created after the load event is called, so avoid asynchronous loading and cache resources.
In the Chrome console, asynchronous loading and cache resources are shown after the red line:

Tip 2: Each page of the PDF report can be represented by a container with a fixed size. For example, if the PDF report will have an A4 format, the container will have the following style:
Tip 3: The PDF files that we will create may have a colors distortion issue. In this case, it is necessary to force accurate colors using the print-color-adjust property.
Tip 4: Avoid chart animations. Each chart library has its way to do it, here is how it can be done with the Chart.js library:
Populating the template with data
Well, let’s now populate our template with data. There are many ways to do it.
➡️ The query string method
An easy way to do it is by sending the data through the URL as a query string. I chose to send a big JSON parameter named data and receive it thanks to the URLSearchParams interface. Then the template can easily be populated with data thanks to native Javascript or JQuery if the template supports it.
It looks great!

Note: Web browsers limit URLs to a maximum length (2MB for Chrome). If you need to send more data, I highly recommend you use the localStorage method.
➡️ The localStorage method
localStorage allows storing data in the web browser session. We are going to read the data as follows:
Server-side implementation
S3
S3 is a scalable storage service for static content, we will store there the PDF files generated by Lambda.
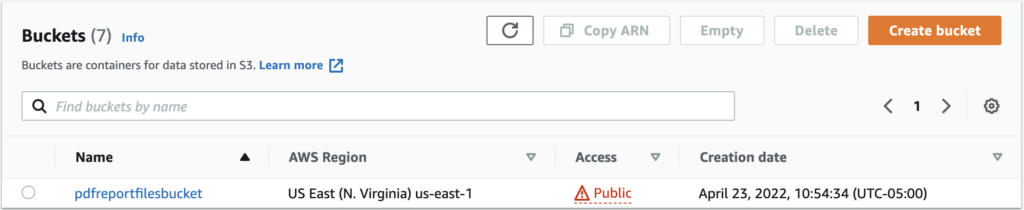
➡️ Bucket
We create a new bucket (aka repository).
➡️ Bucket policy
We edit the bucket policy to allow bucket content only to be read.
The Lambda Layer
Lambda is a great serverless service that allows running code letting Amazon manage server resources for you. But before writing the lambda function, we need to create a Lambda Layer with all the necessary resources to make the PDF generation work.
➡️ The browser
We will use Chrome, which is the worldwide most used browser. There is no official version of Chrome for AWS Lambda, but hopefully, there are some heroes in this world like Marco Lüthy who gave us -mere mortals- a wonderful present: a Headless Chromium version for AWS Lambda.
We download a stable release here and we unzip it.
➡️ Pyppeteer
This is the spicy part: we need to do some hacks to make Pyppeteer work on Lambda. We download the last available version of Pyppeteer on Pypi and we open the __init__.py file.
For an unknown reason, the library version makes Pyppeteer crash on Lambda, so we comment the whole corresponding block and replace it with a hardcoded version number:
The only writable directory on a lambda function is the tmp directory, so we change it by hardcoding the home directory of Pyppeteer:
Note: we could use the userDataDir option of the Pyppeteer launcher to set the right directory, but doing this way we remove the AppDirs dependency and other embedded dependencies.
➡️ Dependencies
Pyppeteer has the following dependencies: pyee, tqdm, and websockets. We download these libraries and place them in the same folder as the headless chromium and Pyppeteer.
➡️ Zip file
The configuration we are building only works with a Python version ≤ 3.7, so our Layer and function will be Python 3.7 compatible.
We place the headless chromium and the libraries in a directory containing the following subdirectories: lib > python3.7 > site-packages and we finally zip it.

➡️ Uploading to the Layer
Great! We finally can create a new Lambda layer: we upload the zip we have created previously and we select Python 3.7 as compatible runtime.
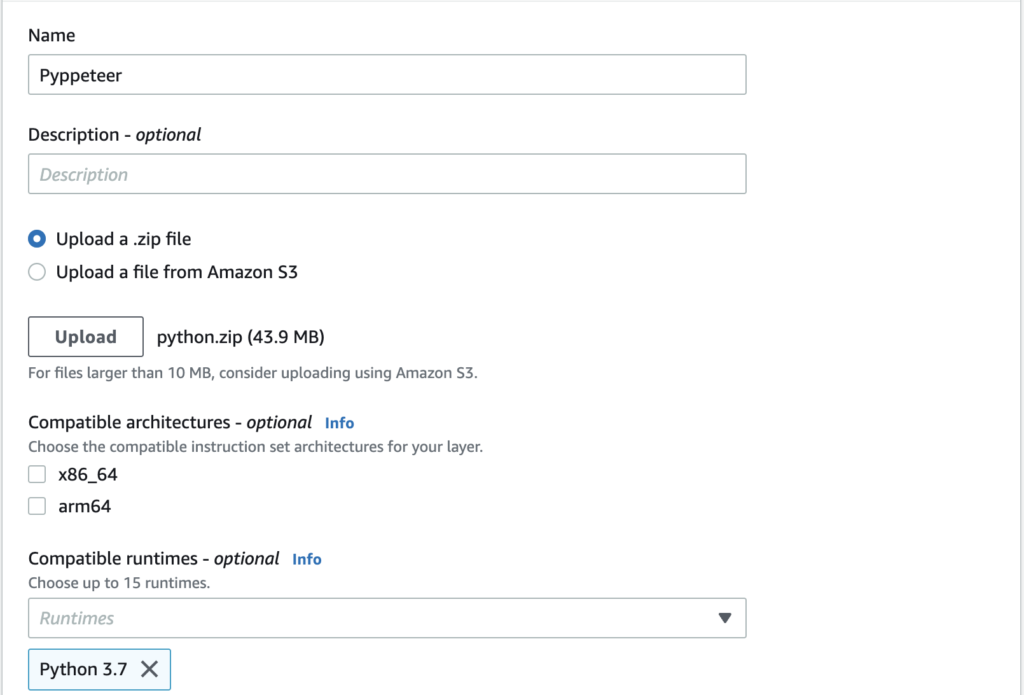
Our layer is ready!!

The Lambda function
➡️ Creating the function
We create a new Lambda function with Python 3.7 as runtime.

➡️ Adding the Pyppeteer layer to the function
Before coding, we have to add the layer we have created previously to the function:

➡️ Coding the function 🚀
Now the most exciting part, let’s code the function!
Notes:
- We assume that we already have the
dataanduser_idvalues. You can check my previous article if you want to make a great integration with other AWS services. - We create a unique PDF file name, concatenation of user id, and actual date.
- We use the quote function of the urllib library to encode the data and then can be part of the URL.
- We use the asyncio library as specified in the Pyppeteer documentation.
- Lambda kept the files we uploaded in the
/optdirectory, so we launch the Headless Chromium calling/opt/python/lib/python3.7/site-packages/headless-chromiumthanks to theexecutablePathoption of the launch function. - We use the goto function to visit the HTML template and the pdf function to generate the PDF content.
- We use the put_object function of the boto3 library to store our PDF file in the S3 bucket we have created.
➡️ Function tips
I let you some wonderful tips you can use in the asynchronous function:
- If you want to retrieve the message displayed by the browser console, use the console event and the ConsoleMessage class,
- If you see some pixelated content in your generated PDFs, use the
deviceScaleFactorparameter of the setViewport function. The default value is 1.0. - If you want to use the localStorage method, go to the page, use the evaluate function to insert the data value in localStorage and go to the page again.
- By default, the PDF file generated has a letter format. You can change thanks to the
formatoption.
➡️ Function role
We go to the role associated with the function and we add the AmazonS3FullAccess policy so that our function can write the PDF file generated in a bucket.

➡️ Function settings
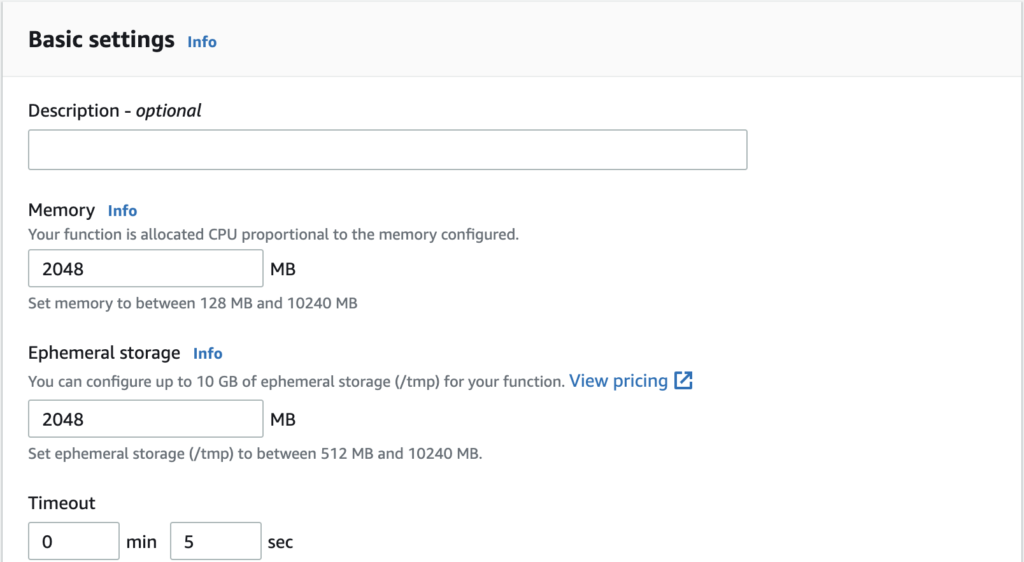
Our Lambda function will run a Chromium instance so it could take a few seconds and use consequent memory.
I found that with 2048Mb of memory allocated, a PDF file is generated and written in a bucket in approximately 3.5 seconds, so we change the function timeout value to 5 seconds.
Final Result
This is an example of a generated PDF from the template hosted on https://alexandrebruffa.com/pdfreport/. It has all we need: user data on stunning charts, custom fonts, colors, and pictures. It has also selectable text and embedded links.
If you try the PDF generation following this article, please show me your PDF files in the comments, I would be pleased to see them!
Closing thoughts
This article showed you how to generate awesome PDF files from an HTML template on AWS Lambda. We learned about AWS Lambda Layers, Pyppeteer library, and some curiosities we found on the way.
During my research, I found this Medium article written by Rafael Brand, it may be useful as a complement to my article.
All ids and tokens shown in this article are fake or expired, if you try to use them, you will not be able to establish any connections.
A special thanks to Gianca Chavest for designing the awesome illustration.




