
Frank Benford was an electrical engineer known for rediscovering a statistical curiosity about the occurrence of digits in lists of data. This curiosity is known as Benford’s law or the law of anomalous numbers, and has applications in accounting fraud detection, criminal trials, election data, among others.
What is the anomaly?
This is very simple. Make a list of everyday numbers you can find like the number of pages of your favorite book, the length of the river near your home, the number of inhabitants of your town, the land area of your country, etc.
Then, calculate how many of those numbers begin with 1, with 2, etc. Common sense would dictate that the distribution of each leading digit is similar, but it’s not. The distribution is logarithmic, as shown below:
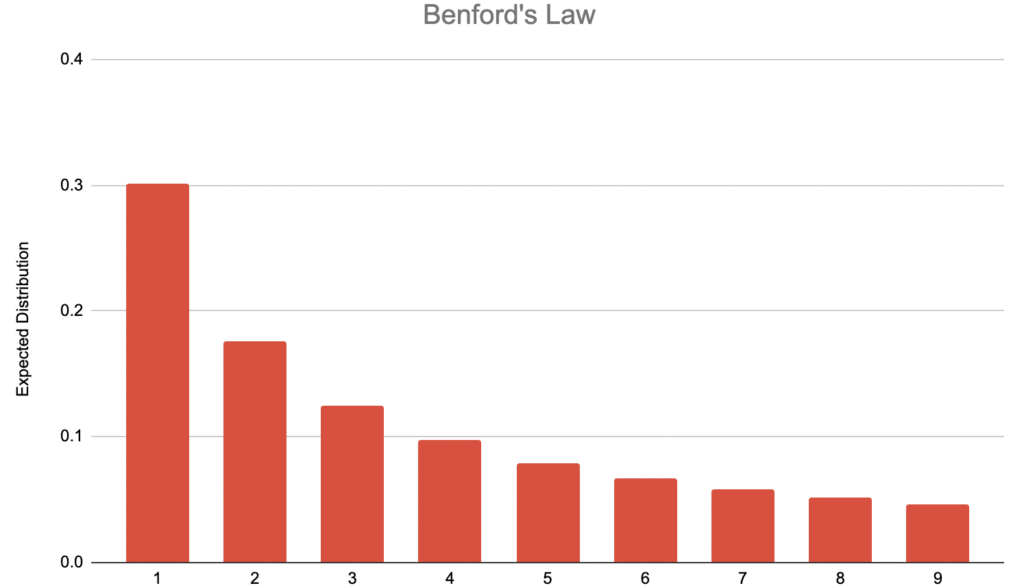
The formula is the following:
d ∈ [1, …, 9]
Notes:
dis an integer between 1 and 9 (0 is not taken into account).P(d)stands for the probability thatdis the leading digit.logrefers to the logarithm base 10.
In other words, it is more probable that your city had 100,000 or 1 million inhabitants than 900,000 or 9 million. It sounds incredible, right? Let’s check it!
Workaround
First, we need to build an enormous list of everyday life numbers. Those numbers can easily be found on the internet, we just have to copy them from websites and then analyze them. But oh boy, it sounds so boring! We want to work with massive data, it could take hours!
Another solution would be working with websites or platforms that have an API like Reddit. However, this is quite limited: not all websites have an API, and we would have to realize one integration per website, which is laborious and eventually boring.
Off-topic: if you want to see a great integration with the Reddit API, I invite you to read the following article by my friend Xavier.
Hopefully, there is a better workaround. Do you remember my previous article about the PDF generation system? Well, we will reuse the main components to create an automated data extraction system.
This is how we will do it: run a Chromium instance on Lambda, visit a list of websites, and retrieve relevant data from them. Then we will process the data and compare it with the expected result.
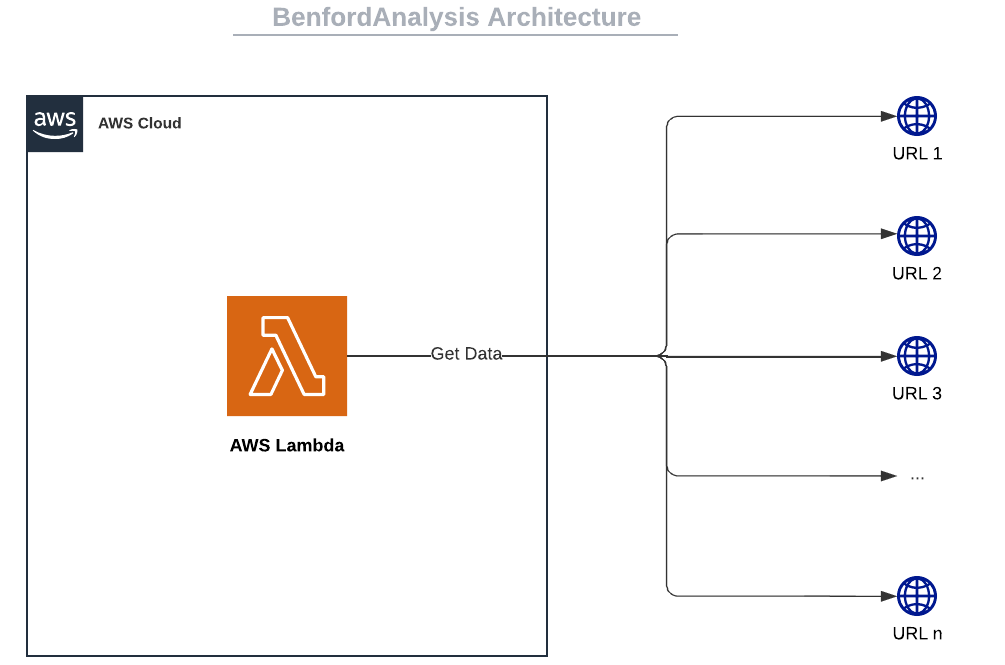
This article will focus on the Lambda part and the data extraction. If you want to make a great integration with Cognito, API Gateway + Authorizer, and an RDS database, I invite you to read the following article:
Selecting the websites
Now, we need to find websites containing relevant data for our experiment. I highly recommend the following:
- Avoid slow-loading websites or websites with some type of Captcha or CloudFlare protection.
- Also, make sure that the data provided is consistent and well-referenced: we need high-quality data to check the validity of Benford’s law.
- Prefer websites with well-formatted data, if possible contained in HTML tables.
The selectors and the Javascript expression
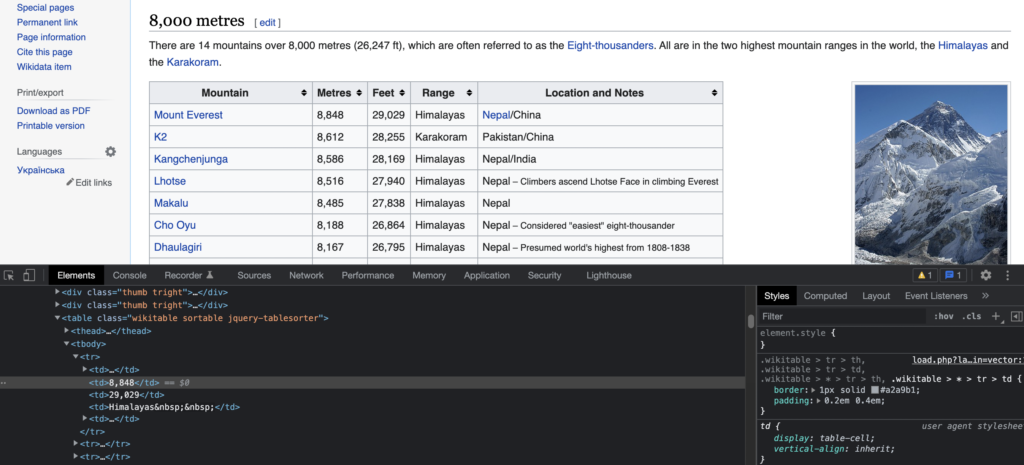
Let’s begin with this great Wikipedia article: List of mountains by elevation.
We can figure out that the relevant data of the article (elevation of each mountain in meters and feet) is located in the second and third columns of several HTML tables with a wikitable class:
We know where the data is, we can now extract it thanks to the querySelectorAll javascript method. We use the CSS selectors .wikitable and td with the :nth-child CSS pseudo-class.
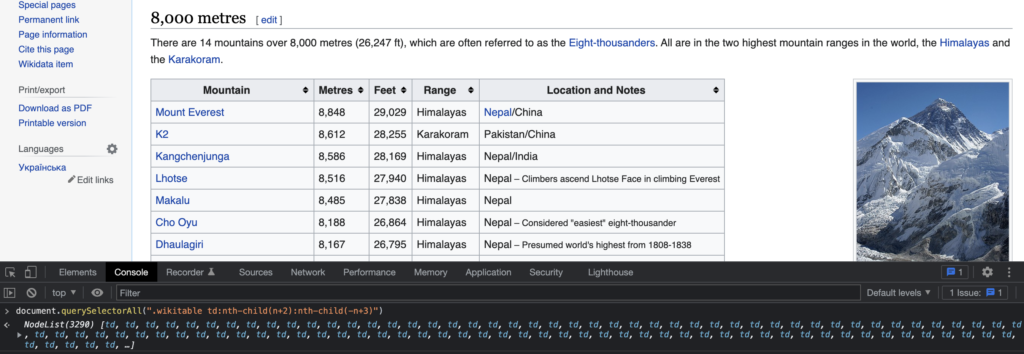
Not bad! We retrieved all the elements we need. Now we will extract the value of each element thanks to the Spread syntax, the map method, and the textContent property:
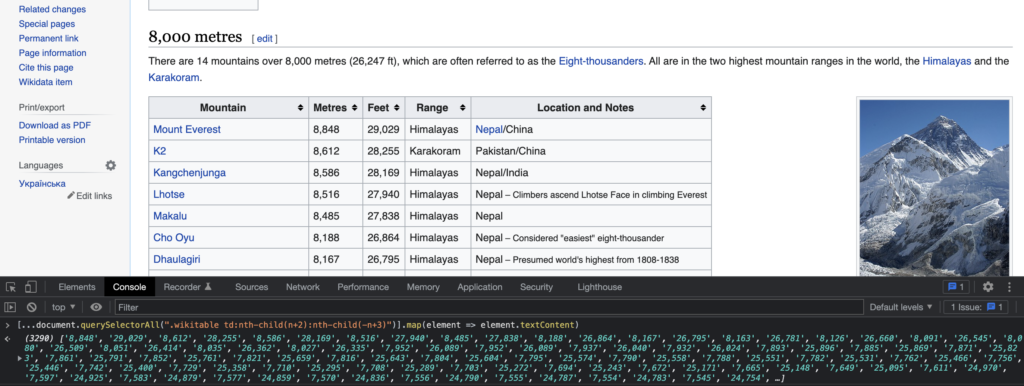
Awesome! Our selectors and Javascript expression are ready, let’s go to the server-side.
The Lambda Layer
We will reuse the same Lambda Layer as in my previous article. It contains the headless Chromium, the Pyppeteer library, and other dependencies.

The Lambda function
The config file
In a config file, we set up a list of websites with relevant data and their corresponding selector.
Note: this list could be stored in the DynamoDB table, you can check the following article if you want to make a great integration with other AWS services.
The code
Now, let’s code the function! 🚀
Notes:
- We create a dictionary with 9 keys, corresponding to the 9 allowed leading digits (from 1 to 9), and their associated values to 0.
- We loop the
websitesvariable, to visit each URL and extract the relevant data. - To realize the extraction, we use the evaluate function of Pyppeteer with the Javascript expression and selectors we defined previously.
- We loop the extracted array of values and we removed the irrelevant ones (negative numbers or beginning with 0, empty values, etc. ).
- We update the dictionary by incrementing the corresponding value.
- We count how many values were removed for informational purposes.
The Test
In this article, we will execute the function on the server-side. So we create a new Test with an empty body:
Result
With the config file we set up, we run the test, and we obtained the following result:
This is massive! We got more than 5000 values. Here is a graphical representation:
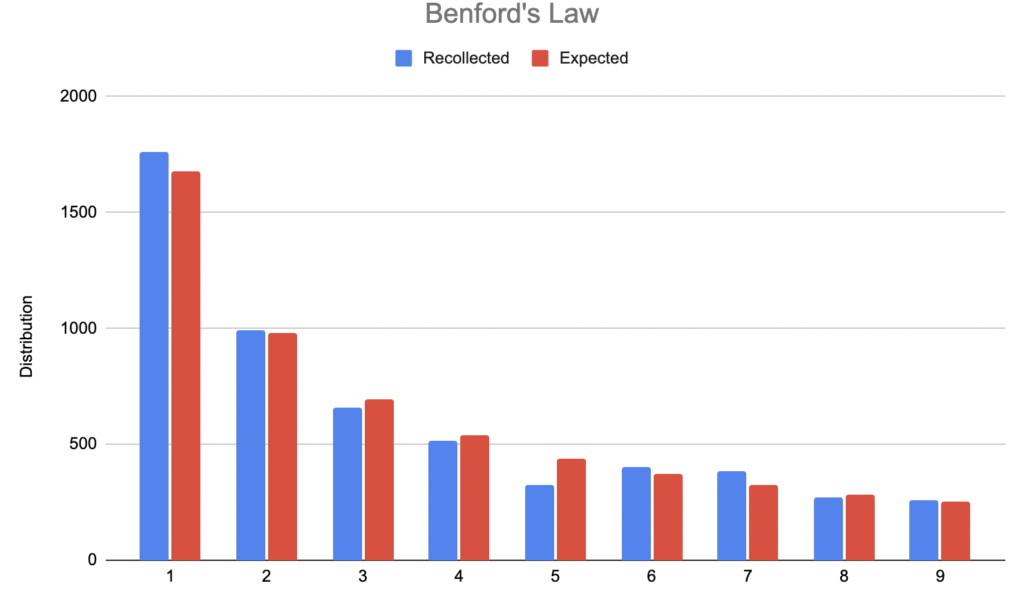
Outstanding!! Benford’s law is real, and we got a result quite near from the expected!
Accounting fraud detection
The anomaly we previously described can be found in the financial statements of a company. It sounds crazy, right? If the anomaly can not be found, that could mean that the statements are artificially created, and this would be a fraud.
Let’s check it with the income statement, the balance sheet, and the cash flow of 4 ginormous companies: Amazon, Apple, Google, and Microsoft. This information is available on websites like MarketWatch or Yahoo Finance.
We got the following result:
We got more than 2000 values, this is a massive experiment! Here is a graphical representation:
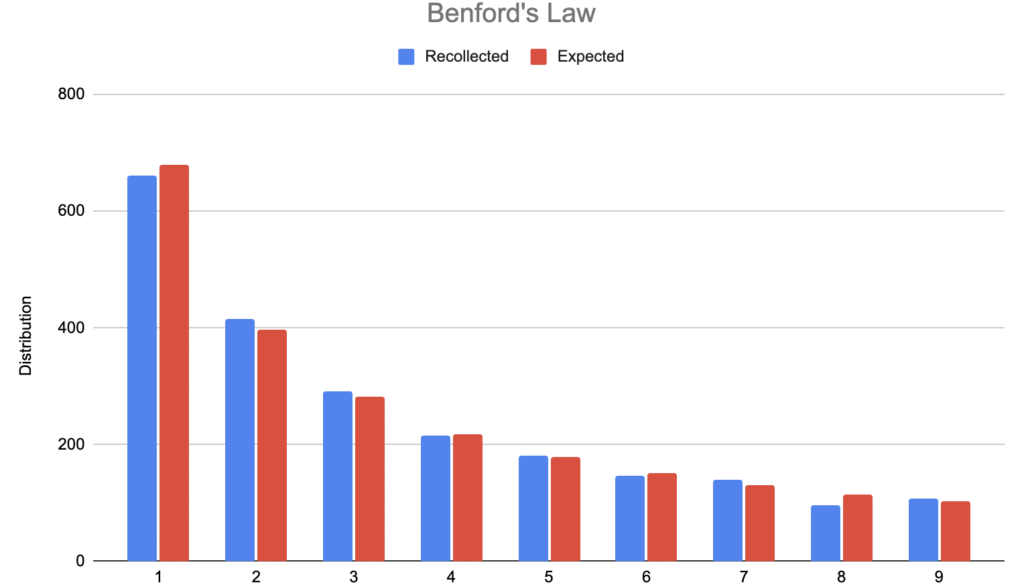
This is an awesome result! Benford’s law works on financial statements and apparently, none of the 4 companies is committing fraud (we hope so!).
Closing thoughts
This article showed you how to extract data from a website on AWS Lambda, and process it. We also learn about the incredible Benford’s law and we could check it with a massive experiment.
If you try the data extraction to check Benford’s law, please tell me which data you used and show me your result in the comments, I would be pleased to see them!
Benford’s law used in accounting fraud detection is brilliantly explained in the movie The Accountant, I highly recommend watching it if you like my article.
A special thanks to Gianca Chavest for designing the awesome illustration.




